


Machine learning (ML) is at the forefront of digital transformation. It uses data and statistical algorithms to teach computers to simulate human intellect without explicit programming. Predictive/cognitive intelligence, image recognition, and “bots” are some of the front-running game-changing ML solutions revolutionizing today’s digital solution set.
The competitive edge that ML brings is only valuable once the model gets deployed into production, and the machine continuously learns (from data sets). Yet, few companies achieve enterprise-wide deployment. From our experience, many companies fall into the trap of piloting ML initiatives but fail to expand deployment, and those who do, struggle with long deployment timelines of months or longer. We have identified six of the top key challenges in scaling models successfully:
- Lack of clarity in the process: It is sometimes unclear who is responsible (e.g., data science, data engineering) and for what (e.g., quality assurance, deployment, release management, maintenance).
- Complexity of the solution: Highly complex solutions necessitate large amounts of data and intricate machine learning algorithms. This complexity may require distributed platforms to operationalize and use of storage to archive metadata to optimize continual re-training and reproducibility of the model.
- Business culture: Decentralized infrastructure with siloed teams may create process fragmentation and duplication.
- Framework/Use of multiple programming languages: Variation in the use of programming languages (e.g., Java, Python, R) may require integration. Further, the choice of machine learning framework (e.g., PyTorch, TensorFlow) may create challenges if the package depends on many libraries, third-party integrations, or specific software versions.
- Hardware: The time needed to train, evaluate, and validate a model may impede computational performance, particularly for CPUs that use a more sequential processing method.
- Modularity: Tightly coupled, non-modular operational systems may prevent adaptability and portability to different operating environments, leading to inefficiencies.
Digitally advanced industrial sectors (such as finance & insurance or social media) have embraced ML technologies but are still facing challenges scaling ML solutions. So, what does this mean for the energy industry, which has experienced recent inertia to digital adoption? Opportunities abound to pivot and leverage the post-mortem lessons learned from these early adopters to redesign optimal ML workflows, tooling, and processes. Although it is tempting to “get it done,” the cost implications, in the long run, show that to “get it right” is ideal. A majority of the time (70%+) continues to be spent on data aggregation and structuring, while a minimal amount is spent on ML logic and deployment. Ineffective coordination and ambiguous communication(s) further hinder the delivery and scaling of ML models.
Deploying ML models at scale requires the development of a validated prototype and the design of a pipeline to automate each step of the prototype’s workflow for continuous monitoring, re-training, versioning, integration, and delivery. The pipeline should allow for reproducibility of inputs and outputs, modifiability of computing requirements, and modularity of components associated with model training versions.
This two-part series presents a broad overview of the sequence for deploying ML models at scale. We use lessons learned from our experiences developing and deploying ML models and principles of machine learning operations. We do not suggest specific technologies or platforms.
Part 1 discusses choosing the appropriate ML solution that aligns with the business problem/goal and the process to develop a validated prototype.
Part 2 delves into the configuration of the ML automated pipeline.
For each part, we provide examples of real-world use case applications.
Scaling Deployment of Machine Learning Models: Ten Key Steps
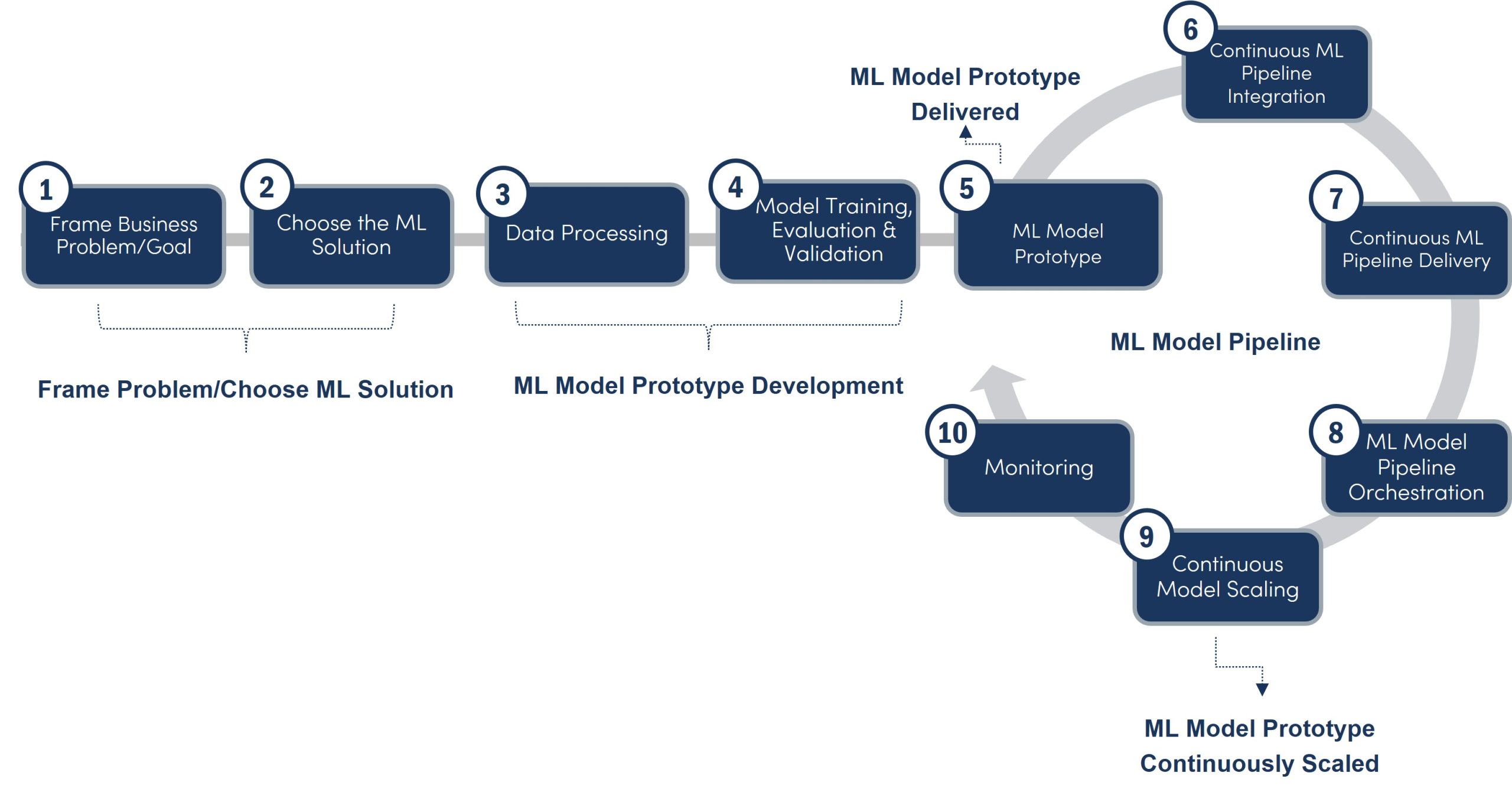
Step 1. Frame the Business Problem/Goal
ML prototype development starts with a core understanding of the problem the business would like to solve or the goal it would like to achieve.
- Who is asking for an ML solution? Is the ask at an executive or operations level?
- Why is the ML solution needed? Is it to address an internal- or external-facing need?
- What level of analytic solution (descriptive, diagnostic, predictive, prescriptive, or autonomous) is needed?
- Who will use the model prototype? And, at what frequency?
- Are there expectations around reporting (or dashboard) requirements?
- What is the nature of data (historical, real-time, or hybrid) needed to address the business problem/goal? Are the data available?
- What type(s) of data (e.g., structured vs. unstructured) is needed? And, at what volume? Where (e.g., data warehouse) are the data stored?
- How is the data quality?
Additionally, at this stage, it is important to assemble the right analytical team to capture ideas and determine the value add of an ML solution. The appropriateness of the solution is dependent on the responses to the above questions. For instance, if the business problem/goal is external-facing and the analytical need is prescriptive. Yet, if the availability and volume of data are lacking, then a ML solution may not be appropriate.
Critical success factors at this step begin with…
A clear understanding of the strategic business direction (will they use an ML or an alternate solution?) is part of the broader digital roadmap to address the business problem/goal.
If an ML solution is a direction the business is headed in, then deliver a strategic work plan for approaching the solution to include, at a minimum: the analytical team involved in the model development and their responsibilities, a development roadmap, success metrics for each development stage, and a plan for regular checkpointing to ensure that all activities, data, processing steps are documented and stored at the appropriate intervals throughout the model development and deployment lifecycle.
Step 2. Choose the Machine Learning Solution
After determining the appropriateness of an ML solution to address the business problem/goal, the next step is to determine what type of machine learning model algorithm to choose.
The machine learning algorithm depends on the analytical solution needed – descriptive, diagnostic, predictive, prescriptive, or cognitive. For instance:
- Classification can help address descriptive/diagnostic analytical needs, such as summarizing and uncovering past/current performance insights.
- Regression can help address predictive analytical needs such as price per oil barrel.
- Decision trees can help address predictive analytical needs such as pipeline risk assessment.
- Clustering can help with diagnostic analytical needs, such as grouping optimal rack wait times.
- Bayes classifier can help with prescriptive analytical needs, such as storage or transportation optimization, by determining the conditional probability of an event happening.
- Recurrent neural networks can help with autonomous solutions, such as monitoring pipeline corrosive health.
The complexity of the ML algorithm is directly related to the resources (i.e., staff and time involved in processing/training the data), computational, and maintenance/sustainability requirements. Essentially, it is important to analyze the feasibility of implementation prior to development.
Critical success factors at this step begin with…
- Hardware and software configurations, serving infrastructure and establishing a common programming language and code base across the analytical team.
- Data processing, such as identification of the predictor and target variables, handling missingness, and standardization.
- Alignment among all key stakeholders (e.g., data scientists, data engineers, business analysts, operational development team, business leads, and business end-users).
Step 3. Data Processing
Data processing begins with a proof of concept (PoC) regarding the ML solution chosen. This PoC will outline an end-to-end development plan for the ML solution to help data science and data engineering teams understand the data processing requirements needed for optimal model development.
Briefly, data processing steps involve:
- Data gathering identifies data sources and defines data inputs/outputs.
- Data integration retrieves identified data and combines all data sets into one or writes queries to import data from a modern data architecture.
- Data exploration looks at the raw data to determine:
-
- The size of the data – This has an impact on the availability of data for training, testing, and validation purposes.
- Dimensionality concerns – Dimensionality might impact the fitness of the model.
- Shape of the data – run descriptive statistics (e.g., mean, median, standard deviation, variance, skewness).
- Cleanliness of the data – check for the data attributes and data missingness, outliers.
- Cleaning the data based on insights gleaned from the data exploration stage.
- Validating the data by applying checks to test for the integrity and quality of the data for modeling.
- Preparing the data for modeling by ensuring proper labeling and standardization, and dividing it into training, evaluation, and validation datasets.
Critical success factors at this step begin with…
- Data quality issues are identified and resolved.
- Collection and storage of the features to aid in understanding model predictability.
- Preparation of data sets for modeling.
- Creation of a metadata store to capture data processing and modeling steps (as well for subsequent iterations).
- Governance of the structure of the metadata store to allow access and understanding of the data across all members of the analytical team.
Step 4. Train, Evaluate, and Validate the Machine Learning Model

For data modeling, use:
- The training dataset for model prediction training. Iteratively apply the ML algorithm chosen and review the performance of the model. If necessary, update the features that are inputted for model learning.
- The evaluation dataset to evaluate the model fitness achieved during model training.
- The validation dataset is used to ensure the optimal performance of the model. During this stage, check for bias, reliability, validity, and potential concept drift.
Additionally, it is helpful at this stage to develop a features database to store all the features during model training.
Critical success factors at this step begin with…
- Outline steps (and including in metadata store) for dimensionality reduction, evaluation for bias detection, how to tune parameters and hyperparameters in the model, which performance metrics to choose, and evaluating model performance.
- Plan for gathering feedback and agreement across the analytical team on the model performance metrics needed for final model selection.
Step 5. Machine Learning Model Prototype
The source code for the ML model prototype is delivered and fed into a source repository at this stage.
Critical success factors at this step begin with…
- Plan for a soft release of a prototype to pilot.
- Plan for identification of business metrics that define the success of the prototype on business performance.
Step 6. Build Continuous Machine Learning Pipeline Integration
Data powers the performance of ML models. Maintaining the reliability and accuracy of the model’s performance requires continual monitoring to inform when to retrain the model with new input data and how to refine that data. Each instance of model training requires developing, testing, and validating code. Once a model is already in deployment, these instances are considered updates, and these updates must be packaged and merged with the ML deployment pipeline. Continuous integration (CI) containerizes the updated code and other metadata (i.e., features, parameters, and hyperparameters) and integrates it into the deployment pipeline. CI ensures readiness for deployment but does not deploy the ML model.
Critical success factors at this step begin with…
- Identify the team responsible for CI.
- Establish a cadence for when updates are integrated with the deployment pipeline.
- Choose software to facilitate continuous integration pipelines that includes automated testing, security assessments, and compliance scans.
Step 7. Build Continuous Pipeline Delivery
Continuous delivery controls the versioning for each implementation of the ML model delivery. Continuous delivery allows the ability to deploy various versions of the ML model at the appropriate time (potentially for different clients or different uses).
Critical success factors at this step begin with…
- Identify the team responsible for continuous delivery.
- Consider creating a versioning workflow that includes a cadence for continuous pipeline delivery.
- Choose a versioning tool that can accept and track a large volume of data and models.
- Create a staging environment to replicate the production environment for quality assurance.
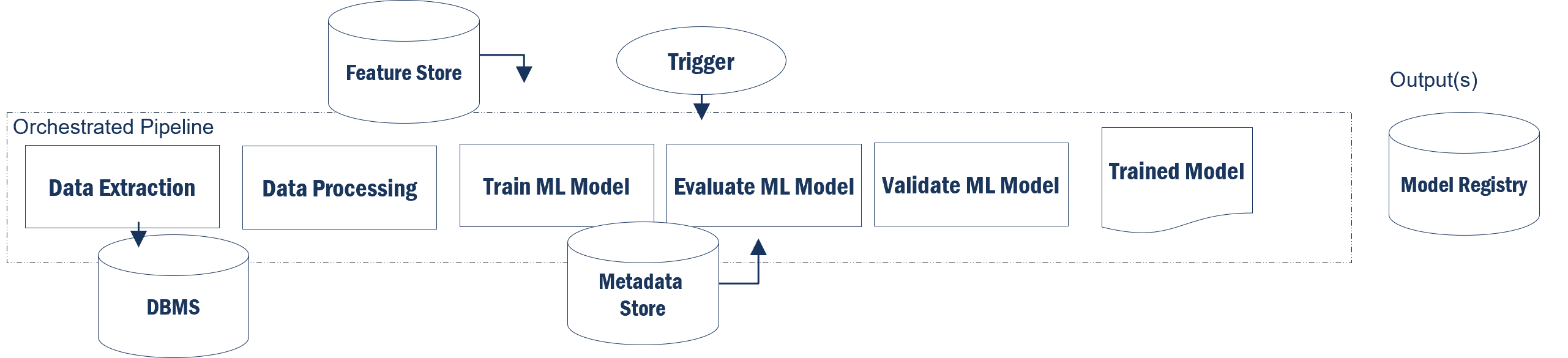
Step 8. Orchestrate the Model Pipeline
Steps 3 to 5 of the machine learning process are orchestrated to allow for repeat execution based on trigger notifications. Triggering is based on performance (discussed in stage 6) declines. These declines would trigger notifications to retrain the model on new data. Outputs are trained models, and the models are stored in a registry which is sent through the pipeline as a prediction service.
Key databases:
- Feature Store: Houses the historical ML features that can be shared and reused (can be online features for real-time analysis or offline (batch uploads).
- Metadata Store: Record of each stage in the pipeline. For example, the inputs for data validation are stored here and the orchestrated pipeline can draw from these inputs to automate the validation during data processing if a new dataset is used for training.
Critical success factors at this step begin with an understanding of…
- Infrastructure cost usage of the automated pipeline.
- The carbon footprint of the models, given model training time, depends on the ML solution (deep learning models may require extended training time).
- Minimum product capabilities are met during each re-run of the pipeline.
Step 9. Design for Continuous Model Deployment
The machine learning model is continuously scaled based on newly trained and validated data that has gone through the pipeline and is ready for deployment.
Critical success factors at this step begin with…
- Determine the cadence for model deployment.
- Develop metrics to assess the outcome of model deployments (e.g., the number of end-users that have adopted the prototype, and the return on investment that the prototype adds).
Step 10. Build for Continuous Performance Monitoring
Continually monitoring the model performance is key. Summary statistics that built various versions of the machine learning model need to be retrained so that it can be refreshed, trained, and changed over time. Performance declines will trigger a re-run of the ML model development pipeline.
Critical success factors at this step begin with…
- Which performance triggers necessitate re-running the pipeline and what steps are needed to identify the triggers?
- Whether running the pipeline requires approval from the businesses’ executive and/or operational leads, or is it purely an analytical team decision?
- When should the re-run occur (evenings, weekends)?
- Which computing and data resources are needed? (i.e., new data input into the ML pipeline)
- Additionally, a clear sustainability action plan documenting roles/responsibilities, and policies for continuous integration/delivery, and scaling of the ML model.
Application of Steps to Real-World Use Cases:
Machine Vision for Natural Gas Networks Using an Infrared Camera
One case study within the Midstream sector (Wang et al) designed a computer vision approach for optical gas imaging leak detection using convolutional neural networks trained on methane leak images to enable automatic detection.
Convolutional neural networks is a category of neural network ML algorithms that uses image recognition and object detection. It works by transforming an input image into a numerical matrix describing features of the image (e.g., size, pixel intensity) and outputs the likelihood of what the image represents.
Like other neural network model types, convolutional neural networks has three general layers:
- Convolutional layer: conducts a convolution operation to capture the most salient information about the image (i.e., a feature hierarchy) and converts it into numerical values
- Pooling layer: reduces the dimensionality of the information from the convolutional layer
- Fully connected layer: conducts classification analysis of the information from the previous layers and outputs classification estimates to predict class labels (i.e., what an image represents)
Considerations for Implementing Machine Learning Vision Solutions:
For companies interested in using an machine learning vision solution, here are some critical considerations for the development of such a solution aligned to the business problem/goal:
- Determine whether the business problem requires a single-imaging processing technique or a more complex solution. Single-image techniques can encompass edge-detection algorithms, which are easier to extract features from an inputted image.
- Ensure that the machine vision platform is adaptable to the range of image and video protocols.
- Utilize model optimization techniques, such as pruning (i.e., removing minor connections and neurons from the model) and quantization (i.e., reducing the precision of learning parameters for smaller model sizes).
Dual Neural Network Design Solutions in Gas Networks
Anderson et al propose a machine learning decision support solution to provide decision-makers with valuable insights into gas pipeline transport problems. Solving gas pipeline transport problems is difficult due to the transient flow of gas in pipelines. The decision support solution uses a dual neural network ML model combined with mixed-integer linear programming (MILP) framework.
Neural Networks are computer simulations that approximate human learning, and consist of an input layer, which receives information for learning, a hidden layer, which constitutes the learning phase, and output layers, which are the expected learning outcomes. Further, neural networks are a form of supervised learning, a process wherein the ML algorithm learns from a training dataset using labeled data (i.e., the correct answer is known). For instance, if an image of pipeline corrosion is marked as “pitting corrosion,” an ML algorithm, using supervised learning, will know how to identify pitting corrosion, and will continually improve its identification of this type of corrosion as more training data are entered.
MILP is ideal for solving complex mathematical problems of time and space discretization, particularly for non-dispatchable energy sources. MILP models discrete decisions into integer variables. In real-world scenarios, they are repetitive in nature and model discrete decisions continually.
Considerations for Scaling Deployment of Machine Learning Neural Networks:
For entities interested in using a neural network ML solution, here are some key considerations for scaling deployment:
- Neural networks may necessitate high computational complexity and storage space. High-performance computing clusters may be essential.
- Model training parallelization to optimize the ML model pipeline for scalability. Essentially, the model training is decomposed, and the computational results are later aggregated for the desired result.
- Potential ways to incorporate parallelism include:
- Inter-model parallelism: copies of the same training model, with different parameters (e.g., number of neurons per layer) are trained on the same dataset
- Data parallelism: the source data set is divided and distributed for training across multiple machines
- Design for queue process to eliminate bottlenecks in ML processes.